DB에 있는 데이터를 가지고 활용하여 분석하는 방법을 소개하겠습니다. 물론 DB에 있는 데이터들을 csv 파일로 저장해서 사용할 수 있지만, 그런 것보다는 DB에 있는 데이터를 직접 불러오는 게 더 효율적이기 때문입니다. 또한, csv 파일이너무 클 경우 대부분의 데이터 핸들링을 DB에서 진행한 후 결과만 가져 온다면 메모리 면에서 훨씬 효율적일 것이라고 예상합니다.
저는 간단히 진행할 것이기에 sqlite 를 활용해보겠습니다.
우선 sqlite 관련 라이브러리를 설치합니다.
| !pip install pysqlite3 |
라이브러리를 불러옵시다.
| import sqlite3 import pandas as pd |
DB 연결
| conn = sqlite3.connect('example.db') |
cursor 등록
*cursor는 SQL 명령문을 실행시킬 수 있는 객체라고 생각하면 될 것 같습니다.
| c = conn.cursor() |
명령문 실행법
| c.execute("SQL명령문") *일반적인 SQL 명령문 예시 CREATE TABLE test (id text, name text, etc text) INSERT INTO test VALUES ('1', 'myname', 'test') *인자 넘겨줄 때 주의사항 python의 %s / % 를 사용하면 SQL Injection의 위험이 있으니, SQL의 ? 문법 사용 t = ('1',) ex) 'SELECT * FROM test WHERE id=?', t *그 외 명령문 활용 purchases = [('2006-03-28', 'BUY', 'IBM', 1000, 45.00), ('2006-04-05', 'BUY', 'MSFT', 1000, 72.00), ('2006-04-06', 'SELL', 'IBM', 500, 53.00), ] c.executemany('INSERT INTO test VALUES (?,?,?,?,?)', purchases) for row in c.execute('SELECT * FROM test ORDER BY price'): print(row) |
테이블이 생성되어 있고, 데이터도 들어가 있다고 가정하고 진행하겠습니다.
sql 결과를 dataframe으로 불러오기
| df = pd.read_sql_query('SELECT * FROM test ORDER BY price',conn) df |
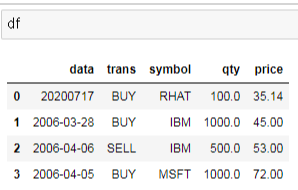
그래프를 그려보겠습니다.
| import matplotlib.pyplot as plt fig, ax = plt.subplots() ax.plot(df['qty'],df['price'], label='line') ax.set_xlabel('qty') ax.set_ylabel('price') ax.set_title('Test Plot') ax.legend() |

추가로, Matplotlib figure의 요소들에 대한 그림 첨부합니다.
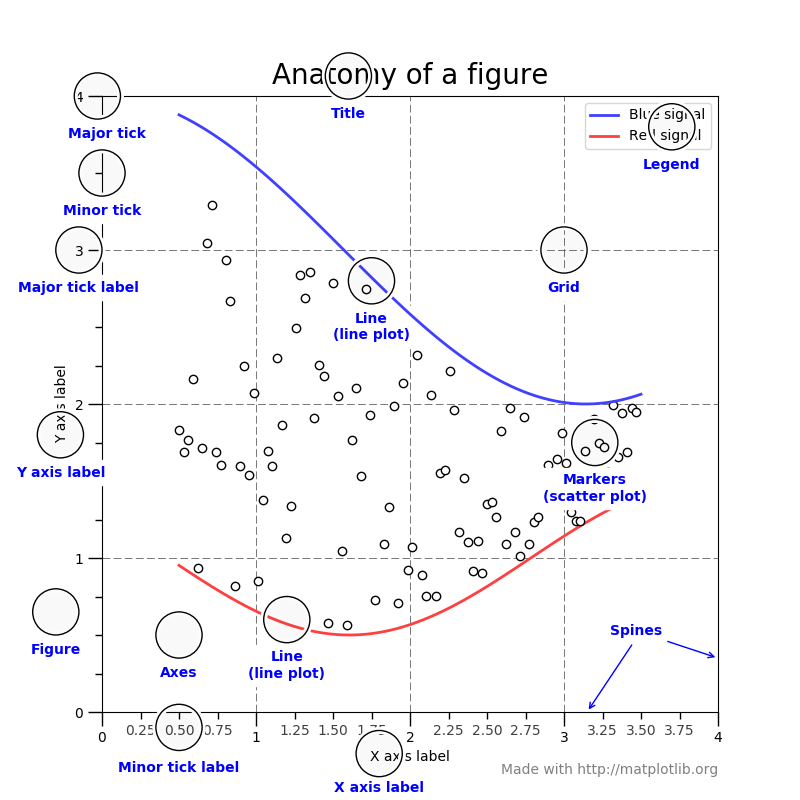
참고:
https://docs.python.org/ko/3/library/sqlite3.html
https://matplotlib.org/tutorials/introductory/usage.html#sphx-glr-tutorials-introductory-usage-py
'Programming > Tip&Informaion' 카테고리의 다른 글
| vscode ssh를 통한 ssh 연결 (0) | 2021.03.19 |
|---|---|
| [zookeeper] standalon 설치 시, FAILED TO START 에러 (0) | 2021.01.29 |
| [scikit-learn] 사이킷런의 regression (0) | 2020.07.10 |
| [DataScience] pandas의 대안은? modin, dask, vaex 비교하기 (2) | 2020.07.02 |
| [환경구축] 아치 리눅스, venv 부터 jupyter notebook 까지 (1) | 2020.06.26 |

